
I realised this morning that a passing comment made in essay 203 about technological innovation—automation—might be expanded. Working through previous essays looking for typos and, indeed, perhaps being the most frequent visitor to my own work is, in one sense very sad, like looking at photographs of yourself. In another way, it is the very subject of this essay.
Data that has been collected is too often assumed to be already in a fit state to be used. This is far from the truth. Data need to be relevant, accurate, complete, correct and current. My research shows that there is as yet remarkably little agreement on even the terminology to use. In general, you want data to serve the purpose to which it is put, so ‘high quality’ data gives you significant confidence that analysis will give results upon which you can rely. Which is, in turn a bit chicken and egg, since you cannot tell if data collected for one purpose is also fit for purposes subsequently chosen.
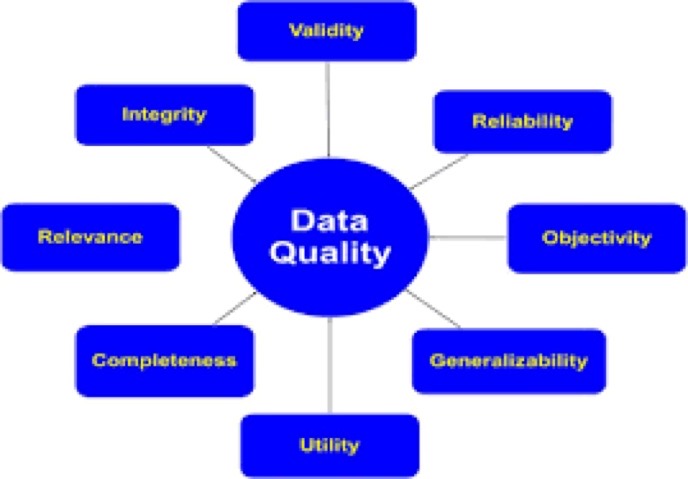
If the ISO 9000:2015 definition of quality is applied, data quality can be defined as the degree to which a set of characteristics of data fulfils requirements. Examples of characteristics are: completeness, validity, accuracy, consistency, availability and timeliness. Source. See also 4
From informatica, I found this (my formatting):
• Data quality refers to the overall utility of a dataset(s) as a function of its ability to be easily processed and analysed for other uses, usually by a database, data warehouse, or data analytics system.
• Quality data is useful data. To be of high quality, data must be consistent and unambiguous. Data quality issues are often the result of database merges or systems/cloud integration processes in which data fields that should be compatible are not due to schema or format inconsistencies. Data that is not high quality can undergo data cleansing to raise its quality.
• Data quality activities involve data rationalisation and validation.
• Data quality efforts are often needed while integrating disparate applications that occur during merger and acquisition activities, but also when siloed (!sic) data systems within a single organisation are brought together for the first time in a data warehouse or big data lake. Data quality is also critical to the efficiency of horizontal business applications such as enterprise resource planning (ERP) or customer relationship management (CRM).
• When data is of excellent quality, it can be easily processed and analysed, leading to insights that help the organisation make better decisions. High-quality data is essential to business intelligence efforts and other types of data analytics, as well as better operational efficiency.
Point: that establishing whether data within a system is consistent is something that is difficult for automation to do. Let us imagine a form is to be filled in and that this data is input to a database. Establishing whether a piece of data is complete is easy and should be automated. Establishing whether the form is correctly filled in is another matter. Finding internal inconsistencies might be automated, might become automated, can become automated, but that automation implies quite a lot of work to be done. It makes very little progress in establishing whether the aforementioned form is appropriate, or whether it correctly describes the situation that the form is to represent.
My brother¹ has given me many examples that demonstrate fixable issues, but his most often revisited topic is to do with addresses. You have an address; is it an ‘acceptable address’? Does the postcode match the street? Is the house number in that postcode? Does the person claiming to be at this address match previous data for this address? Is this person also found at another address? Which leads you to the knotty problems of just who is this person: is <this> the person in <this record>? Is <this person> the same as <this other person of the same name>? How do we identify whether these people are the same or different? Are the unique identifiers actually unique? Does anyone have two such identifiers?
You begin to see some of the problems. Bad enough if you are well and have time to establish your position (think trying to log on to a system), but not at all the same experience if you are trying to solve an immediate urgent problem such as a medical emergency. Of course, the paperwork will catch up later, but many (expensive) tests might be avoidable if you can be identified as <this person belonging to that set of records already held>.
So you see a need for some exclusive identifier for a person. Much of the UK state activity finds that a National Insurance number is such an identifier. That rather assumes that the system for providing such identifiers succeeds: succeeds in giving one person one NI number; succeeds in there being one number for one person; succeeds in finding people to give numbers to; succeeds in people actually remembering their number. For many systems, there will be service (of some sort) available if ‘you’ (the person requesting service) is ‘in’ the system and a different sort of service if not, probably requiring a new entry into the system and all the proof that requires.
I wrote in essay 203 ² that my thinking suggested that the solution to non-standard problems within an automated system is for the system solution to be ‘pass it to the human’. Think of the levels of help we need at the supermarket ‘self-service’ checkout. This is, certainly effective use of staff, for one person is now serving many customers per time unit. If you have tried one of the ‘scan as you shop’ systems, you may recognise that there is a significant level of trust being given to the shopper, and you may feel that the person providing customer service for those who have scanned is largely idle. The throughput of customers is even higher than the other self-service methods (the scanning process is moved more in-store, within the aisles; all that is happening at the checkout is checking and payment). So here, the human assistant is providing a data quality check, among other things such as social interaction, political glad-handing and assistance with confused customers. Which might be perceived as a social service as much as a commercial need.
I am wondering whether ‘fetch the human’ is the role in which many of us will find future work. Fixing the non-standard problem is, I suspect, not only ‘difficult’ for automation, it is generally, at the moment, expensive. Does that mean that as soon as an issue becomes non-standard there will be cost implications? If so, then that may also mean that some of us ‘customers’ will abandon a ‘purchase’, a seeking of service in some sense, simply because as soon as we are non-standard we cannot afford the response. This is a common issue with repairs.
I have a mundane example. I have been trying to make a repair on our oven. One of the little buttons that works the clock is broken (indeed, it was so when we bought the house). The particular button is the one with the most use, being the one that you push every time you use the clock (reset the timer, adjust the clock, etc); the break was not a great issue and the fault could be avoided with a matchstick. but that is not a fully functioning oven and we have the house to sell. We are not going to replace the oven for the sake of a button. So the drive to fix this is (i) completeness for sale and (ii) simply that this should be fixed. I found a supplier of buttons, itself ridiculously expensive. The issue is how to pull out the broken stem still inside the clock unit of the oven. Actually more difficult than I thought and fairly soon I’ve made the problem worse, not better. I now need to replace the whole switch, or the whole clock unit. Can I find the part? Can I even identify exactly what the oven is? Actually, no I can’t, because the sensibly placed identification plate has been cleaned to blankness, perhaps an indicator of age. Time to ‘fetch a human’, I think. Sure enough. this is expensive, like £150. The bright, experienced human agrees that I have identified the problem and agrees that I have identified the oven unit (but for the last character not listed on the supplier site) and agrees that I have identified this as a problem needing fixing — since I last turned off the power for some other reason, the clock is now an essential to have fixed for the oven to do anything functional. He provides a fix (bypass the clock) pro tem and we the issue of ‘can we replace the clock’ becomes ‘does the supplier have any for this discontinued model’ which may become ‘will the supplier permit the use of a non-standard clock’. To which the answer is, basically ‘no’, which means that the expert has a solution but the supplier, who certifies the expert for service, will not permit the expert to satisfy the customer. Which means that replacing the matchstick actually means replacing the oven.
That is what I mean by non-standard becoming expensive. £150 for 15 minutes, most of which was my questioning the result.
Hence we have the throw-away society. Perhaps our collective use of the internet will steadily produce solutions (“Don’t throw away the matchstick”, “embrace your matchstick”, “ways to decorate the essential matchstick for a ***** oven”), much as I found in trying to repair vertical blinds (mostly, use a paperclip).
Which is maybe not to do with data quality. Or maybe it is.
How do we establish that data is correct? Generally by having some facility for checking. A little redundancy of information is very helpful. Back to addresses: you’re making an entry on an online form and you’re asked for your address. So you put in your postcode and ‘search for address’; this assumes that the database in use has your address. What if it doesn’t? What can you do? Even if you have put in your address and house number, might there be sense in being asked for the first line of your address, just to provide a check that your street belongs in that postcode? Just how stable do you require postcodes to be? I was present in Plymouth when we in boarding collected our very own postcode; the consequences even ten years ago were surprising. I was twice refused service because ‘I clearly didn’t exist’ — my postcode was not in the database, meaning their copy of another database; their failure to update becomes my problem. Sure, this problem went away eventually, but not at all quickly. It did help substantially when one could talk with the fetched human (some were even fetching) and be permitted to explain why the postcode didn’t exist on their system. But then one also needed to know how to fix their new problem; updating the database somehow involves people a very long way up the responsibility tree, possibly even outside the business you’re dealing with – too often quite beyond possibility.
Don’t just ‘fetch the human’, fetch one that can do what is needed to be done, even if indirectly.
So I see a possible future in which many of us are employed in ‘data quality’. Unfortunately, the examples I have given so far fall into two categories: (i) the data is out of date (ii) it is commercially too expensive to fix the immediate problem.
Datum, Data
One handicap of a classical education is that one knows the singular is datum - a single measurement. Many measurements are data; but I’m using it as a non-count noun most of the time. When it is countable I use the plural, when not, the singular. or, at least, that is the intention.
So what class of data quality is commercially worth fixing?
We are aware of ‘big data’ as a term. What does it mean?
Suppose it means something as simple as ‘we have a big data base and we can ask it all sorts of questions’:
From the relatively trivial (but quite important in some contexts)
How many duplicate entries do we have? How many people are logged on more than once?
Are any of the inactive ‘customers’ actually deceased? Can we remove them?
Are any of our apparent duplicates actually not duplicates?
Are any entries that we think are different actually the same (a sort of opposite to a duplicate)?
To the relatively important
How many customers who <have this property> will <exhibit this property>?
– which covers a multitude of possibilities where the first and second properties could be
bought this will buy this
have this illness also have this illness / propensity for this illness
live here have received <this service>
The resulting data —the results caused by the data and associated decisions— might well mean that your postcode denies you some facilities available in an adjacent address, or mean that you are somehow labelled in ways that you resent (for similar reasons, denial of service seems to me the most likely). This might also make you the target of some commercial campaign, but, compared to how you are taxed, or have access to education or policing or health care (any of the state functions typically enjoyed in the UK), this is pretty trivial.
How do ‘we’ maintain databases? How do we check that the data we are using on which to base decisions are actually what we think they are?
Wimbledon has been on this week, The Lions tour has just completed; F1 is in action again. Sport is, compared to health care or national security, a harmless place for data. Yet, just within tennis, the breakdown of data into analysis provides apparent detail that allows the observer to comment and to conclude. But I wonder at the levels of subjectivity, as I wonder at the apparent sophistication of the data collected.
<Player> ran <distance> during <game interval (say point, game, set). How is that measured? (back foot at start to front foot at finish? centre of mass movement? Gross approximation given to far too great a level of precision?) What is the error and the cumulative error? Will anyone take any notice? Is this number fit to be compared with another number of the same label? You can be sure it will be.
<Team> has gained <this much> ground so far in this rugby match, versus <number> for the opposition. Same set of questions, all to do with data quality and appropriate use of that data.
Is that gain of ground a measure of success? Does it convert to points? Perhaps the use of this to measure the work involved in gaining points?
In tennis, it becomes apparent (perception) that all points are not equal, that matches turn sometimes on very few points. Much of this is psychological, some of it is luck; for many the joy to be garnered from watching sport is the unpredictability of the result, as very small differences accumulate into results.
So I query whether the ‘wonderful’ access to data actually enhances our appreciation of what is occurring. I think it does, if we are able to understand what it is that the data is telling us. I have issues with subjective labelling, such as ‘aggressive’ strokes in tennis. If we can measure the way in which the body is moving as a stroke is played, say towards or away from the net (how is that done, what approximations took place and so-on are all questions not answered), does that become converted into some other label describing something quite different such as emotional temperament? I can see the value in, say, counting how many first serves go in, but I can also see that, if we agree that not all points are equal, that this very count is unhelpful if the failure rate goes up (for losers) and down (for winners) at crucial parts of the match. How can you possibly turn this into measurement when it is a qualitative matter not a quantitative one?
How does a commercial enterprise put value on the results produced by what is loosely described as ‘big data’? Who is it that is justifying the work involved? How many decision-makers assume the correctness (validity, precision, completeness, quality) of the data when making fine distinctions between possible actions? How would they know? (Will they ever find out that they were wrong, if they are?).
Is this issue of data quality much the same as the issues of why it is that electorates have been making decision that apparently fly in the face of ‘sense’? I think it may well be.
I can also see that perhaps employees need to begin to understand how very important it is to provide quality data. Too often the process of making a data return is so far divorced from any use of the data (as in ‘I do not care, it has nothing to do with me’) results in the data being largely useless. That, in turn, means that there must be probably continuous education given to those who provide data, and who input data, to make every effort to make its quality as high as is possible. Which in turn begs questions about the value ascribed and costs attached to that data. To an extent, the term ‘big data’ is used to refer to information collected in passing, somehow incidentally – we have all this data, can we use it for something? – such as turnover on supermarket shelving, which starts off as a route to better ordering / supply cycles but then heads off towards renewed learning about customer habits (e.g. picking products at eye height). It strikes me that using data for purposes for which it was not intended is more than a little like extending a graph beyond its data range.
I can see me returning to this topic.
DJS 20170712
Research to do. Possibly several more pages to write.
call this a draft, a work-in-progress.
I replaced the top image, which had been copied from 235, but on upload, the image from 234 appeared instead in the synopsis list. Weird. Eventually it will be the intended more relevant image.
From a corporate point of view, there are issues when databases are combined (I think this entirely obvious). Apart from field mismatches there are multiple issues to do with what the original purpose of the data collection was. If you have two sets of similar data based on different criteria, who is to say that these can (or cannot) be combined? You can be sure that if they look similar they will be combined, but the subsequent drop in data consistency is, I think, not recognised; Because stuff that looks like answers to the question you are researching have come from different sources, you are unaware whether they really apply to the thing you are researching. It also strikes me that it is likely that the person to whom the decision to combine (or not) two databases probably has remarkably little idea of the suitability or match of the two sets of data. All of which leaves a whole new ball-game, trying to make databases homogenous (make fields be reliable as to content so that your next question elicits a useful answer). It also begs the question—actually a whole raft of questions—about whether anyone will notice whether the ‘answer’ they have dragged from the data is in any sense a correct one. Garbage in, garbage out has long been true, but wrong is not the same as not-quite-right. When so many questions require binary answers (is/is not), far too many cases of any description are going to be shoved into a category simply because ‘that is what the system wants’; meaning, really, ‘making a new category is too difficult’. Which really is a reflection more of a failure to understand the value of good data. I can see a lot of work being repeated off into the future. Perhaps the best that we can hope for is that large databases will produce ‘answers’ that we can then attempt to validate: “It looks, from the data, as if <this> is true; let’s go and find out”. I would deem that as sensible. But far too often, sense is abandoned in pursuit of immediate answers. In a sense, we too often do not recognise the value of an accurate answer. Perhaps that is a management role not often enough practised?
Does this mean that the oft-resented element of school maths, “Does the answer make sense?” might eventually prove to be the very best question learned at school.
DJS 20170719
http://searchdatamanagement.techtarget.com/definition/data-quality
https://en.wikipedia.org/wiki/Data_quality
1 One of my brothers worked for an extended time on data quality within the Health Service. I will seek his input but, since he is newly retired, making comment on past work is something he does not want to be bothered with, being still in the after-glow of not having to go to work and ‘do stuff’. So I will write away and let him respond, rewriting as necessary after whatever response occurs.
2 Essay 203 includes “So if we have the routines (algorithms) to find the data in which we are interested, the combination of high-echelon human and computer with access to large databases will generate powerful information. Which leaves a lot of work to be done on data quality, which will largely not go away⁹.”
It goes on I looked just a little and found the tern ‘novelty detection’. Quite what one would do with such an event (‘pass it to the human’ is my first thought) is less clear. Right now, that would be sufficient; send the mobile, flexible, adaptable human unit to go find out what might have caused the novelty event. No doubt that will raise the productivity of the humans, while steadily lowering the number of humans required for any given (low-level maintenance) task.
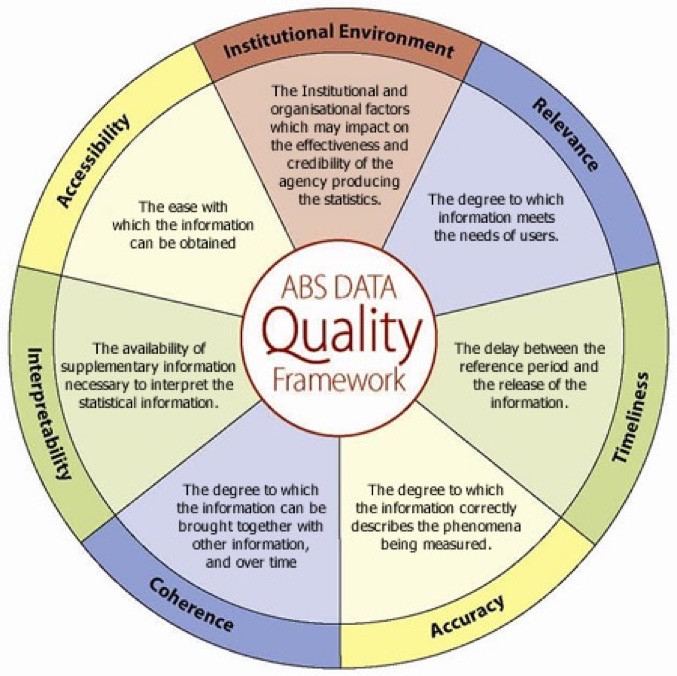
3 Issues to do with addresses in a database:
Does the postcode exist (does it check with some other list)?
Does the postcode include the address being checked?
Does the address (with or without a postcode) have a postcode?
Is the address unambiguous? Does the address exist (a hard one to check)?
Do we have other records for this address? Do any of these have someone with the same name (including of sufficiently similar name to perhaps be the same person?
What do we do when someone has a postcode our database doesn’t recognise? We might reject some as impossible (XY99 0AA) recognise some as perhaps newly allocated (PL4 6RP, allocated in Nov ’03 and still missing from many places; PL46RQ removed in ’05). SK39AC is not allocated but is consistent. XY is not in the postcode list, nor is ?X except EXeter, OXford and HalifaX (no, Uxbridge is UB). ZE is Shetland, but there are no other Z?. One way of seeing what does/does not exist is to look here, but I do not know any way of guaranteeing how up to date it is – what do you do when you know you have been given a new postcode? How do you convince others your code is newly valid? Fetch the human, obviously.
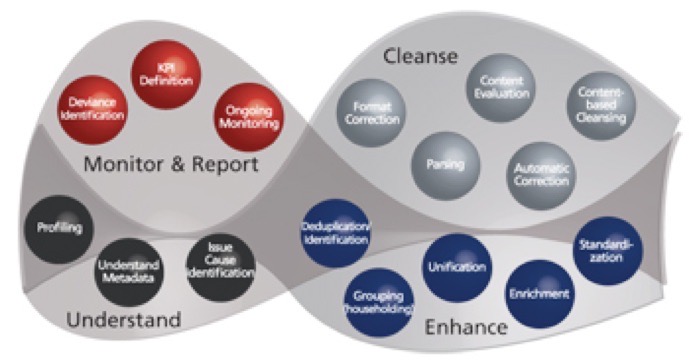
Then there are issues with what we might call exclusivity:
Does the system have anyone else with the same name (including one so similar it may be the same person)? Are there people at the same address with the same name (and again, close enough to confuse)?
Where we have people of the same name—or sufficiently similar names that they might be the same person—do we have other information that may help distinguish them? Date of birth, for example? Might there be twins or triplets?
At what point can we trust the customer to provide us with genuine information? Do we demand independent ratification of anything they provide as additional information or can we trust that what they say is correct?
4 ISO 8000 [not 9000] specifically addresses data quality. See. Source. Worth a Read
Further reading:
http://www.dpadvantage.co.uk/2014/12/23/iso-8000150a-framework-for-data-quality-management/ a place to start, I suggest.
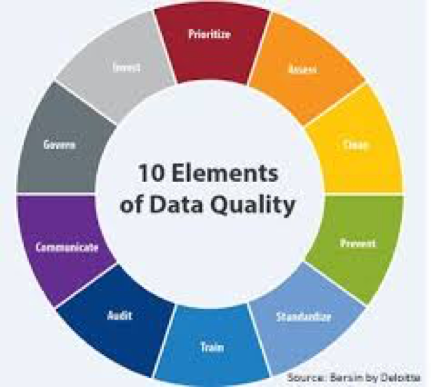
On the right are some of the many images available, which give you a flavour of the blurring of terminology. Google images.
